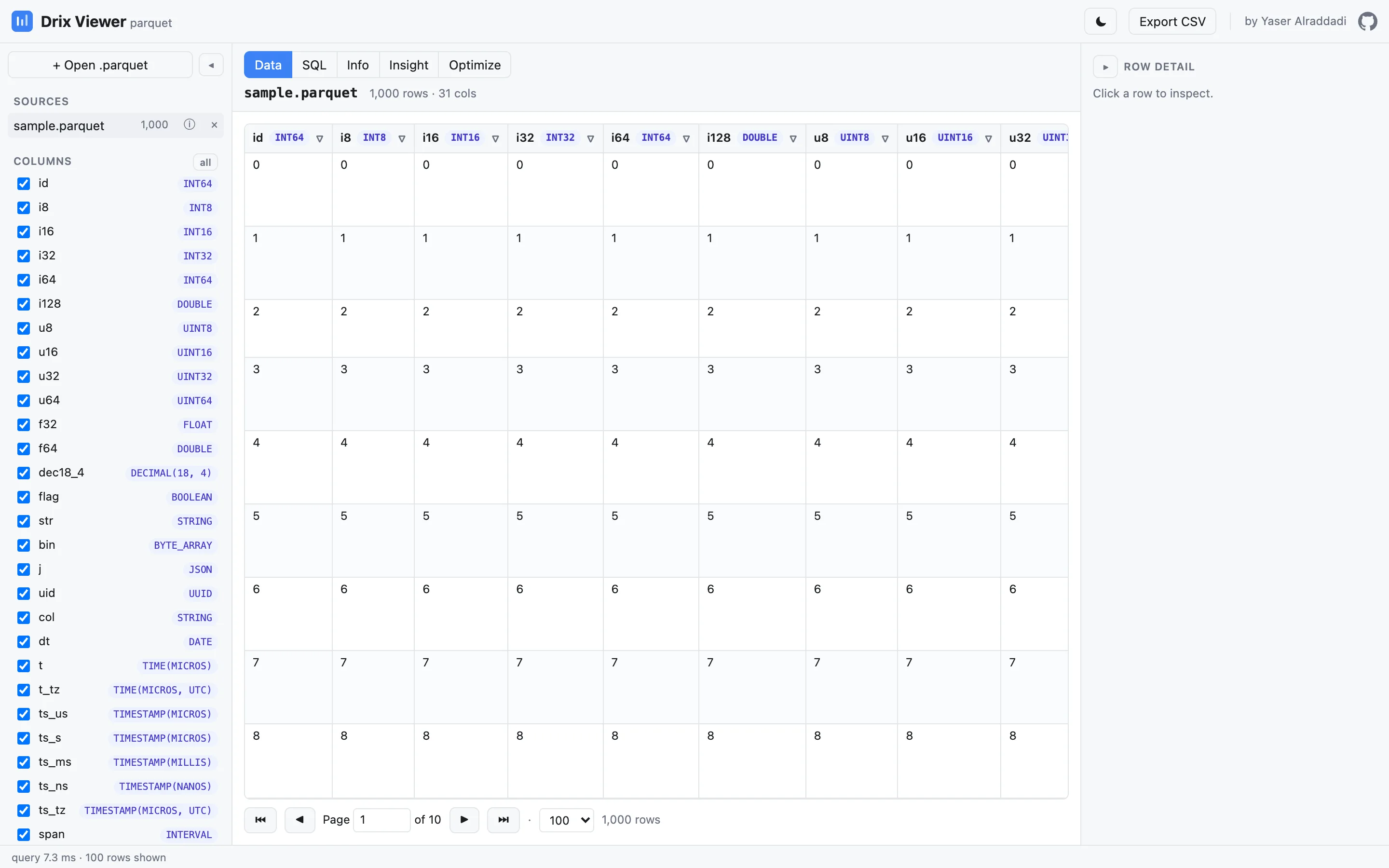
Data grid
Browse millions of rows
Sort, filter and paginate huge files instantly. Every operation compiles to DuckDB SQL, so the grid only ever holds the page on screen — a 50-million-row file feels like 50.
100% local · no upload · no backend
Drix opens .parquet files right in your browser — browse and query them
with SQL, inspect the format, optimize for size and speed, and surface insights.
Powered by DuckDB-WASM, with nothing ever leaving the page.
Data grid
Sort, filter and paginate huge files instantly. Every operation compiles to DuckDB SQL, so the grid only ever holds the page on screen — a 50-million-row file feels like 50.
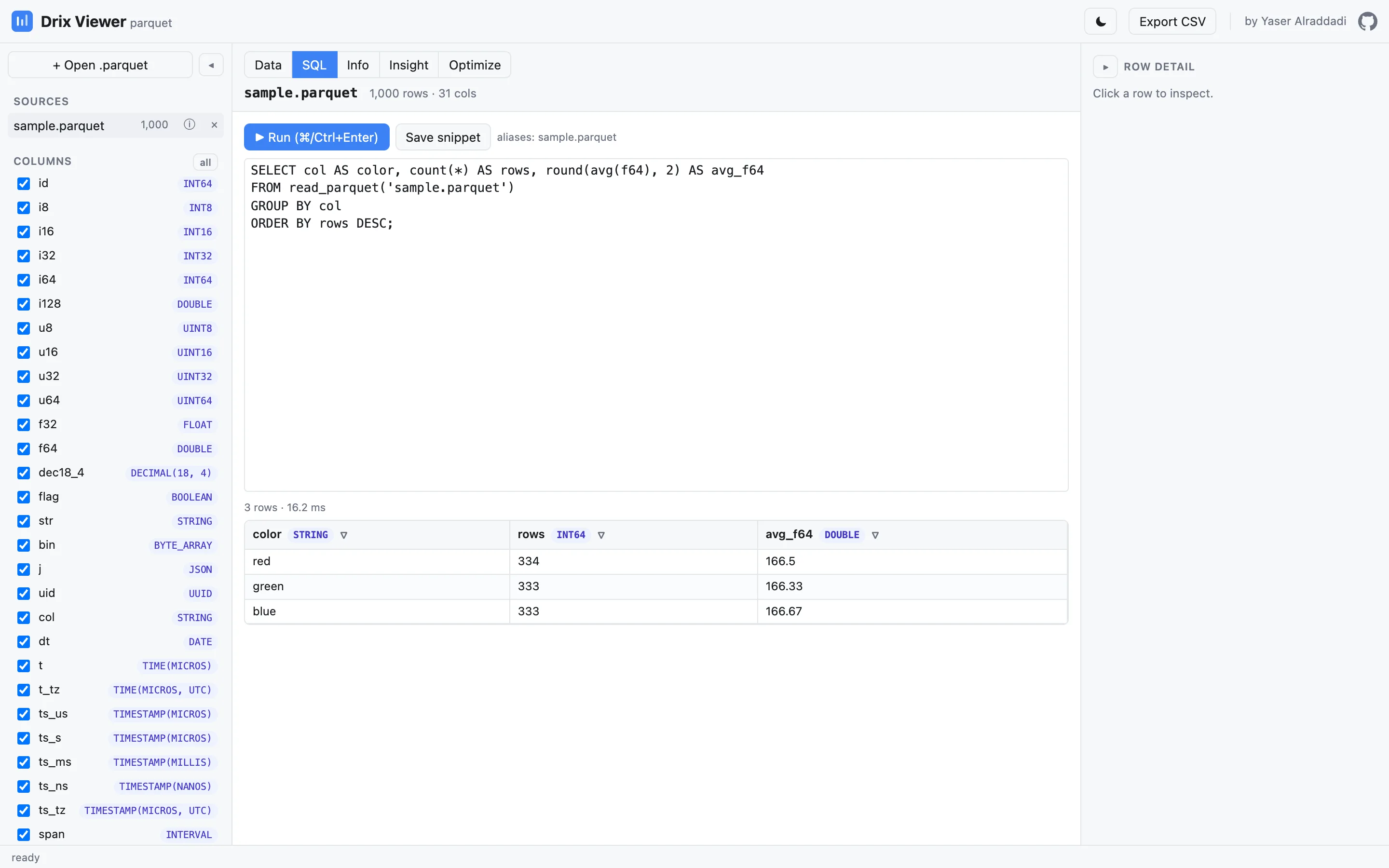
SQL console
Run any SQL against your loaded files, JOIN multiple parquets together,
and save snippets for later. Results render in the same fast grid.
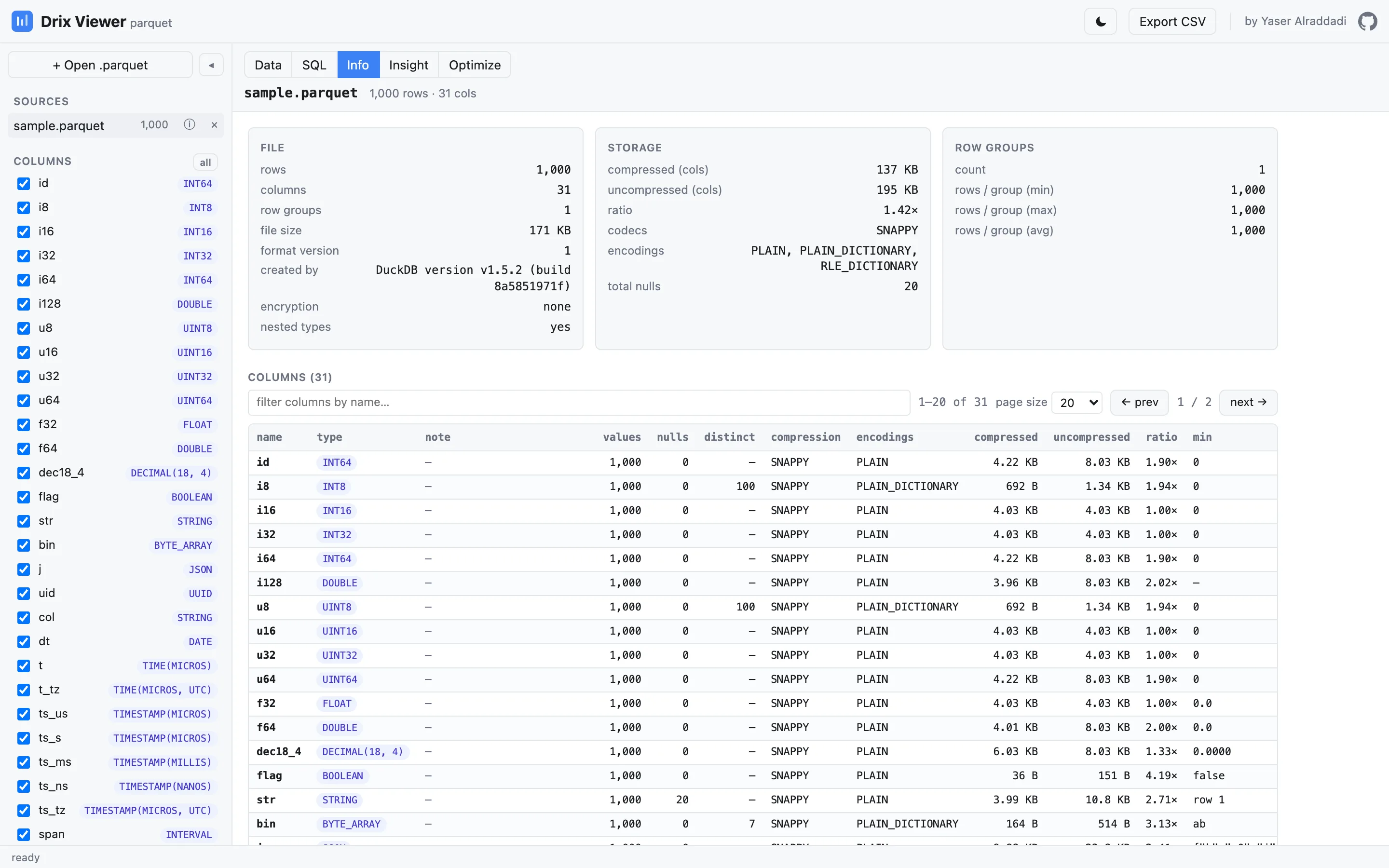
File info
Every byte of Parquet metadata: compression codecs, encodings, row-group layout, column statistics, bloom filters and decoded key/value pairs.
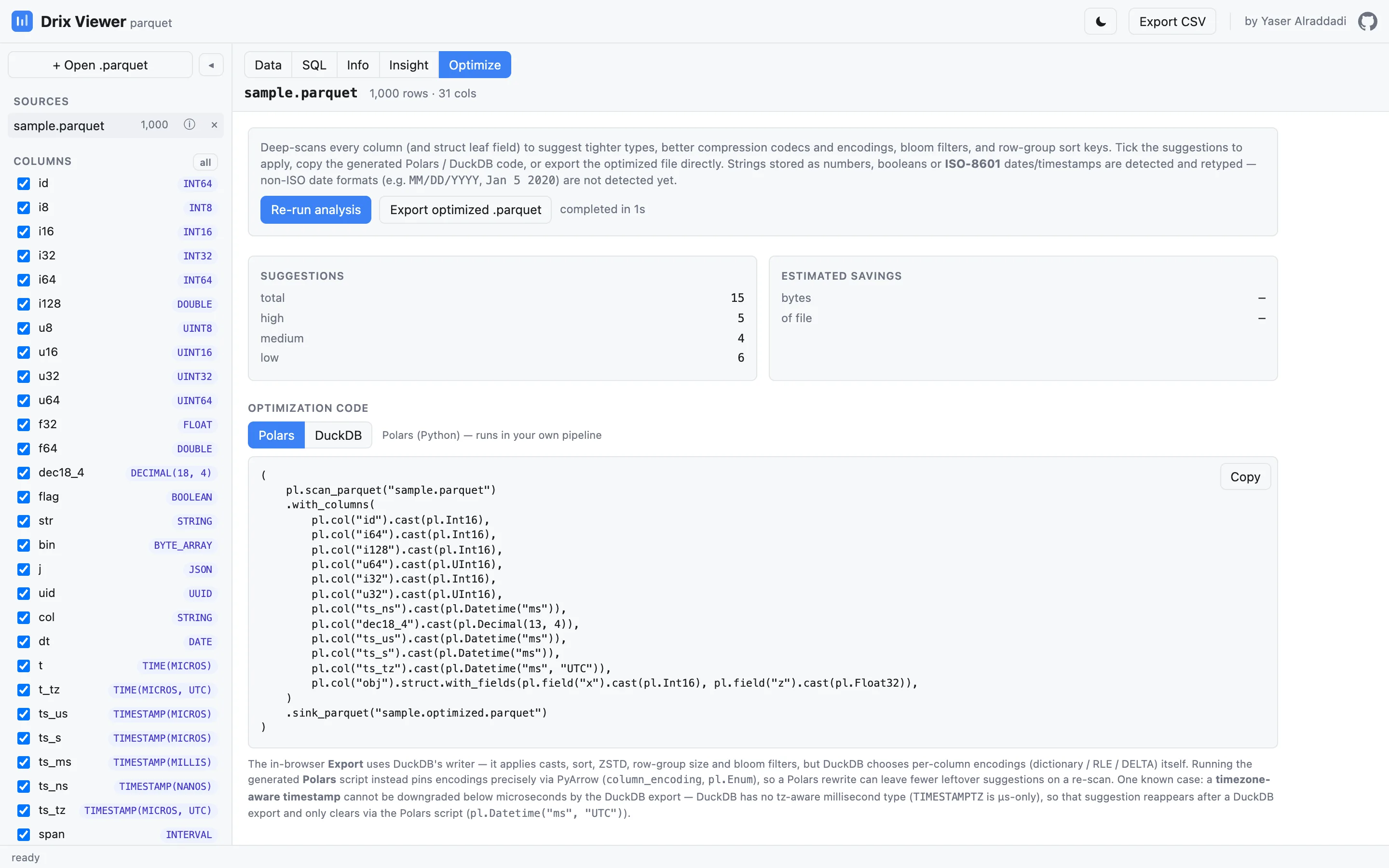
Optimize
Drix deep-scans every column for better compression codecs, encodings and row-group layout, estimates exactly how much space you'd save, then generates ready-to-run Polars or DuckDB code to rewrite the file the better way.
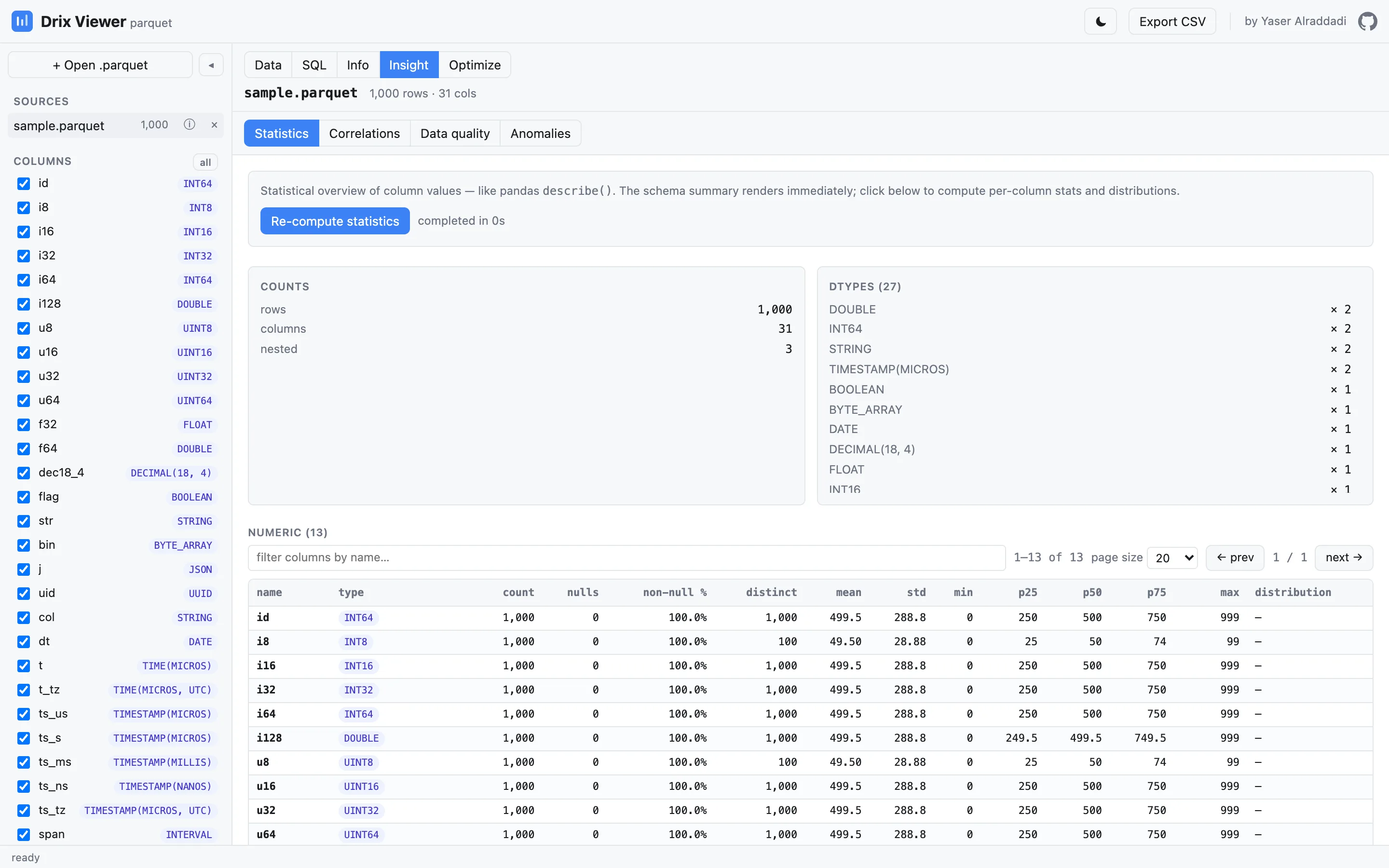
Insight
On-demand column statistics (like pandas describe()), correlation
analysis, data-quality checks and anomaly detection — computed in-browser, with no
notebook required.
BOOLEAN through INT128, precision-preserving DECIMAL, UUID/JSON/ENUM, every timestamp unit, and nested STRUCT/LIST/MAP as expandable JSON trees.
Column headers show the file's true Parquet logical types — not a JavaScript-runtime approximation.
Click to sort, shift-click to add a secondary sort, with numbered indicators.
Text gets contains, numbers get range operators, dates get a picker, booleans get a tri-state.
Export exactly the rows your current filter and sort describe, in one click.
Files stay in WASM memory. It works offline once cached. There is no server.
It runs in your browser. Nothing to install, nothing to upload.